이번에 PyTorch관련 코드를 보는 중 파편화된 지식이 많은 것 같아서 시간을 내서 PyTorch에 대해 한번 싹 정리해보자고 마음 먹었었습니다. 유튜브에서 안그래도 예전에 정리할때 보려고 추가했던 아래 링크:
https://youtu.be/k60oT_8lyFw?feature=shared
를 보고 기존에 애매하게 알던 것들을 정리했구요.
정확하게 함수에 대한 인자나, 아주 세세하지는 않지만, 저 처럼 좀 파이토치에 대해 듬성듬성 알고 계시는 분들에게 좋은 것 같습니다.
PyTorch
- 페이스북이 루아 언어로 개발된 Torch를 파이썬 버전으로 개발
- 초기에 Torch는 넘파이 라이브러리처럼 과학 연산을 위한 라이브러리로 공개
- 이후 GPU를 이용한 텐서 조작 및 동적 신경망 구축이 가능하도록 딥러닝 프레임워크로 발전시킴
- 파이썬답게 만들어졌고, 유연하면서도 가속화된 계산속도를 제공
PyTorch 구성요소
- torch : Main namespace, Tensor등 다양한 수학 함수가 포함
- torch.autograd : 자동 미분 기능 제공 라이브러리
- torch.nn : 신경망 구축을 위한 데이터 구조나 레이어 등의 라이브러리
- torch.multiprocessing : 병렬처리 기능을 제공하는 라이브러리
- torch.optim : SGD를 중심으로 한 파라미터 최적화 알고리즘 제공
- torch.utils : 데이터 조작 등 유틸리티 기능 제공
- torch.onnx : Open Neural Network Exchange, 서로 다른 프레임워크 간의 모델을 공유할 때 사용
Tensor
- 데이터 표현을 위한 기본 구조
- 텐서는 데이터를 담기위한 컨테이너로써 일반적으로 수치형 데이터를 저장
- 넘파이의 ndarray와 유사
- GPU를 사용한 연산 가속
- x = torch.empty( n, n ) → 초기화 되지 않은 텐서
- x = torch.rand(n,n) → 랜덤으로 초기화된 텐서
- x = torch.zeros(n,n, dtype = torch.long) → Datatype이 long이고 0으로 채워진 텐서
- x = torch.tensor([3, 2.3]) → 입력한 값으로 텐서 초기화
- x = x.new_ones(n, n, dtype=torch.double) → 1로 채워진 텐서
- x = x.rand_like(x, dtype=torch.float) → 기존의 x텐서와 shape이 같지만 랜덤으로 나오는 텐서
- x.size → 텐서의 크기
- Datatype of Tensor
|
Data type
|
dtype
|
CPU tensor
|
GPU tensor
|
|
32-bit floating point
|
torch.float32 or torch.float
|
torch.FloatTensor
|
torch.cuda.FloatTensor
|
|
64-bit floating point
|
torch.float64 or torch.double
|
torch.DoubleTensor
|
torch.cuda.DoubleTensor
|
|
16-bit floating point
|
torch.float16 or torch.half
|
torch.HalfTensor
|
torch.cuda.HalfTensor
|
|
8-bit integer(unsinged)
|
torch.uint8
|
torch.ByteTensor
|
torch.cuda.ByteTensor
|
|
8-bit integer(singed)
|
torch.int8
|
torch.CharTensor
|
torch.cuda.CharTensor
|
|
16-bit integer(signed)
|
torch.int16 or torch.short
|
torch.ShortTensor
|
torch.cuda.ShortTensor
|
|
32-bit integer(signed)
|
torch.int32 or torch.int
|
torch.IntTensor
|
torch.cuda.IntTensor
|
|
64-bit integer(signed)
|
torch.int64 or torch.long
|
torch.LongTensor
|
torch.cuda.LongTensor
|
CUDA Tensor
- .to 메소드를 사용해서 텐서를 장치로 옮길 수 있음
device = torch.device(’cuda’ if torch.cuda.is_available() else ‘cpu’)
y = torch.ones_like(x, device=device)
######
x = x.to(device)0D Tensor
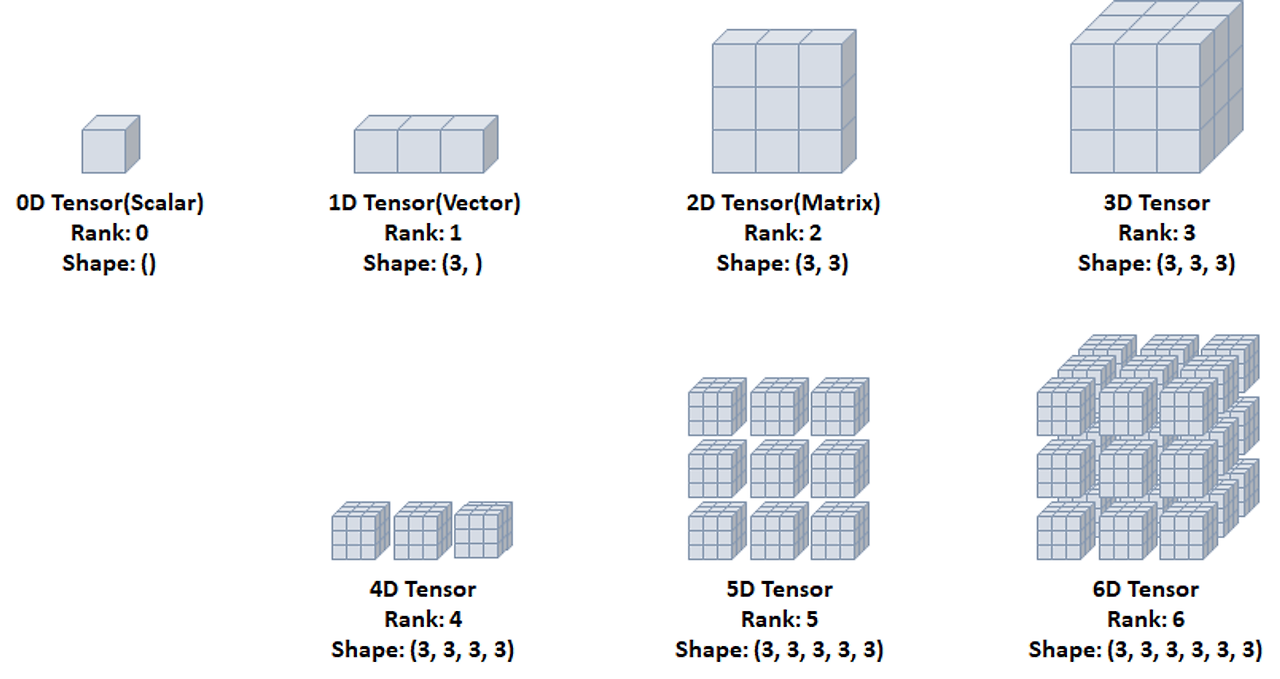
- 하나의 숫자를 담고있는 텐서, 축과 형상이 없음
1D Tensor
- 값들을 저장한 리스트와 유사한 텐서, 하나의 축이 존재
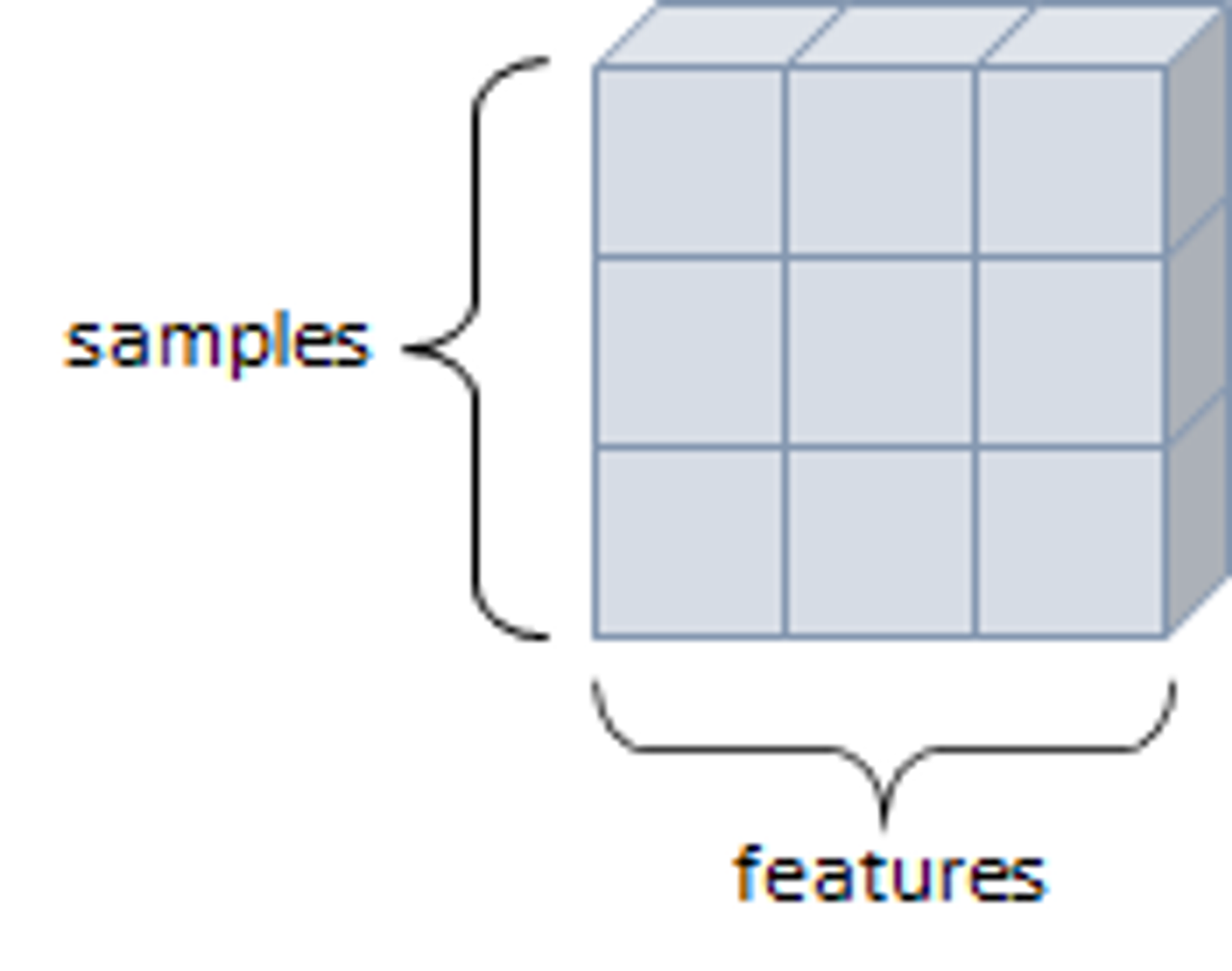
2D Tensor
- 행렬과 같은 모양, 두개의 축이 존재. 일반적인 수치와 통계 데이터셋이 해당, 샘플과 특성을 가진 구조로 사용
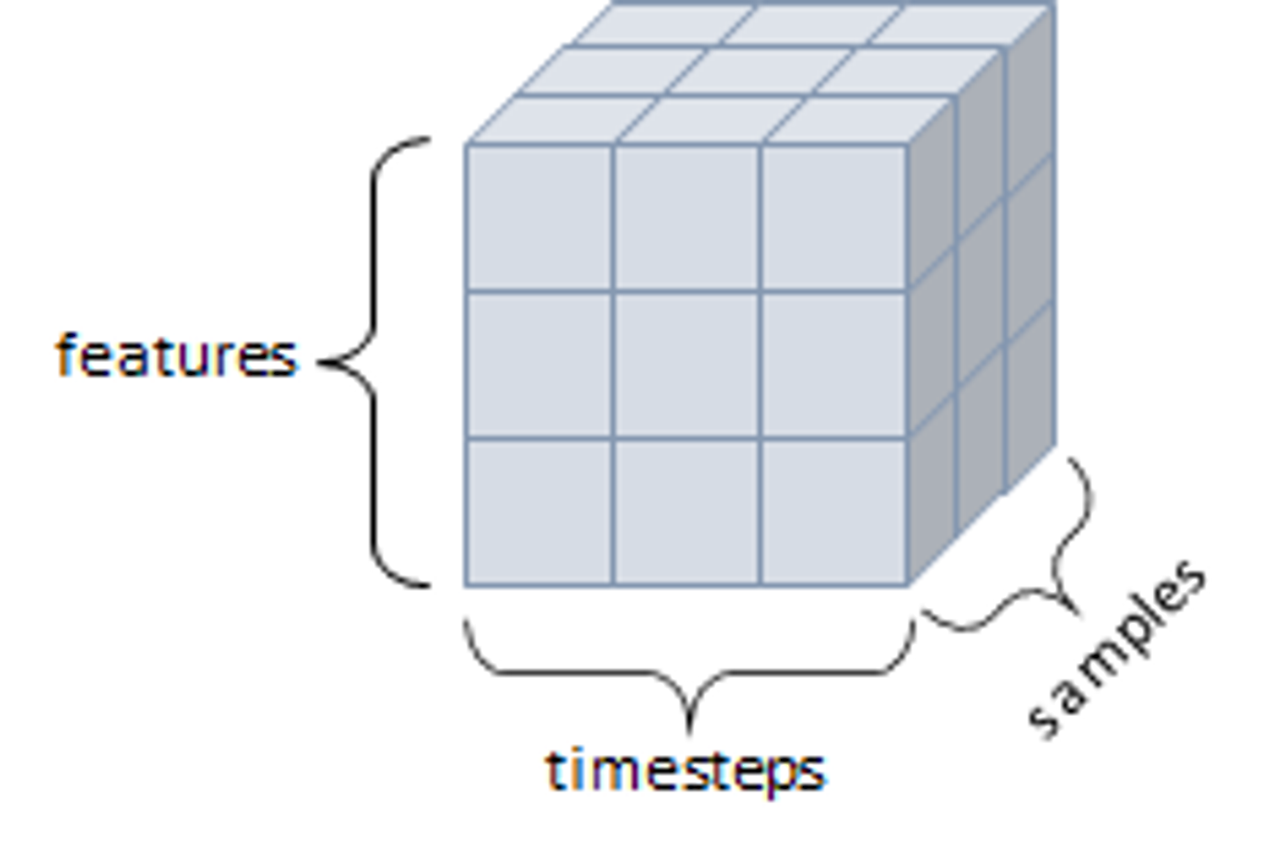
3D Tensor
- 큐브와 같은 모양으로 세개의 축이 존재, 데이터가 연속된 시퀀스 데이터나 시간 축이 포함된 시계열 데이터가 해당
- 주식 가격 데이터셋, 시간에 따른 질병 발병 데이터 등이 존재.
- 샘플, 타임스탭, 특성을 가진 구조로 사용
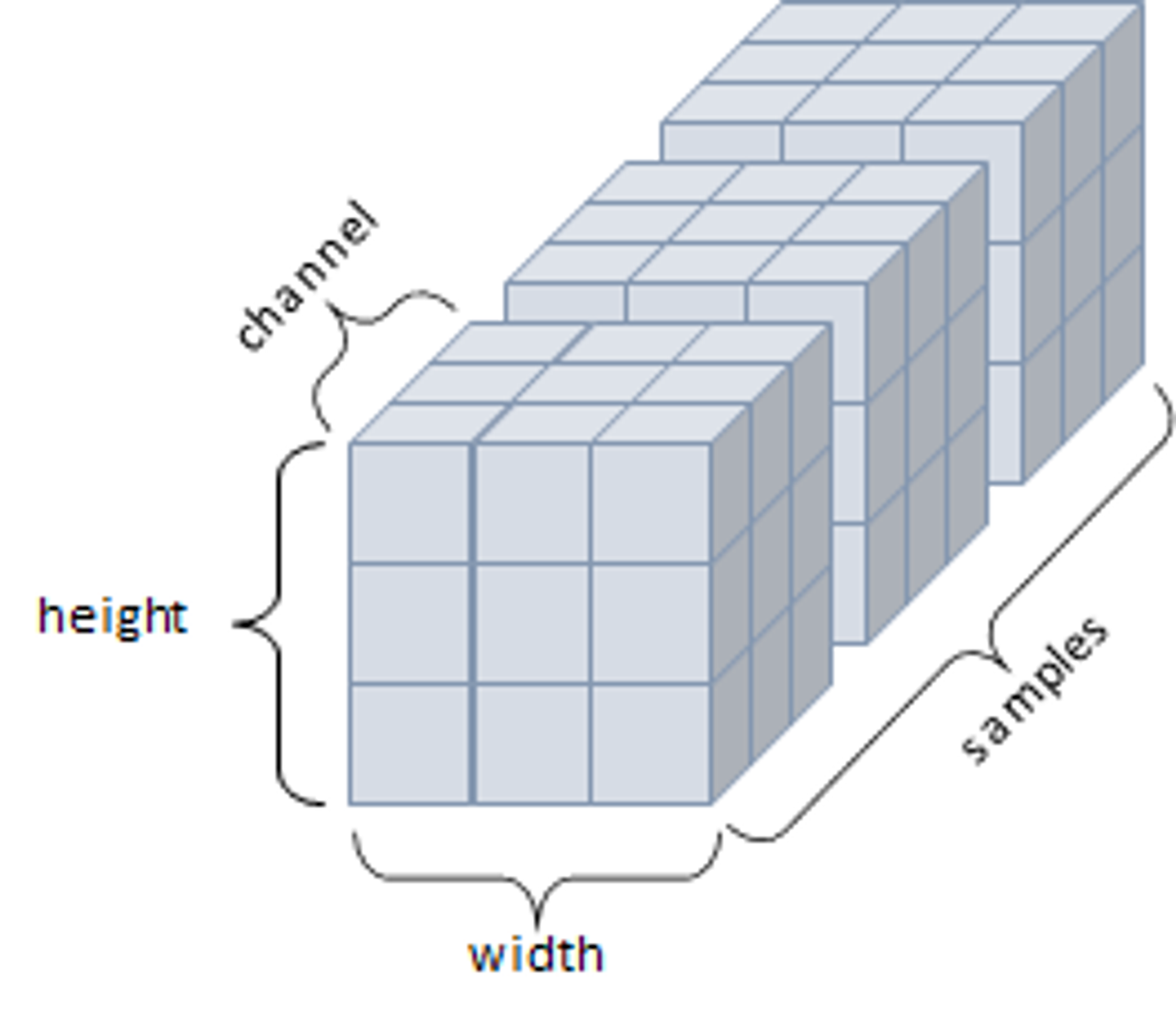
4D Tensor
- 4개의 축, 컬러 이미지 데이터가 대표적인 사례
- 주로 샘플, 높이, 너비, 컬러 채널을 가진 구조로 사용
5D Tensor
- 5개의 축, 비디오 데이터가 대표적인 사례.
- 주로 샘플, 프레임, 높이, 너비, 컬러 채널을 가진 구조로 사용
텐서의 연산
- 텐서에 대한 수학 연산, 삼각함수, 비트 연산, 비교 연산, 집계 등 제공
torch.abs()
torch.ceil() #올림
torch.floor() #내림
torch.clamp() #찝기
torch.min() ; torch.min(dim=0 or 1) #Argmin
torch.max() ; torch.min(dim=0 or 1) #Argmax
torch.mean()
torch.std()
torch.prod()
torch.unique() # 중복제거
torch.add()
torch.add(x, y, out = result) # result에 x+y 넣기
y.add_(x) #y에 x를 바로 더하기
torch.sub() #add와 동일
torch.mul()
torch.div()
torch.mm() #내적 Matrix Mul
torch.svd() # Singular Value decomposition텐서의 조작
- Indexing : Numpy처럼 인덱싱 형태로 사용가능
- View : 텐서의 크기나 모양을 변경. - 기본적으로 변경 전과 후의 텐서 안의 원소 갯수가 유지되어야함 - -1로 설정되면 넘파이와 동일하게 유추해서 계산
Copy
x = torch.rand(4,5)
y = x.view(20)
# 20개로 펼쳐짐 (20,)- item : 텐서의 값을 가져옴. 대신 단 하나 가져오라고 명시를 해주어야함 스칼라 값 하나만 존재해야 item() 사용 가능
- squeeze : 차원을 축소(제거)
- unsqueeze : 차원을 증가(생성)
tensor = torch.rand(1,3,3)
t = tensor.squeeze()
#squeeze shape = [3,3]
t2 = t.unsqueeze(dim = 0)
#t2 shape [3,3] -> [1,3,3]
t3 = t.unsqueeze(dim = 2)
#t3 shape [3,3] -> [3,3,1]- stack : 텐서간 결합
- cat : 텐서를 결합하는 메소드 (concatenate) 넘파이의 stack과 유사하지만, 정하는 dim에 따라서 어떤 방식으로 쌓는지가 다름 해당 차원을 늘려준 후 결합
a = torch.randn(1,3,3)
b = torch.randn(1,3,3)
c = torch.cat(a,b,dim=0) # shape (2,3,3)
d = torch.cat(a,b,dim=1) # shape (1,6,3)
- chunk : 텐서를 여러개로 나눌 때 사용
- split : chunk와 동일한 기능이지만 조금 다름 Chunk의 경우 몇개로 나누는지가 핵심이며, Split의 경우 몇의 크기로 나누는지가 핵심
Torch ↔ Numpy
- Torch tensor를 Numpy의 array로 변환 가능 numpy() = Torch → Numpy from_numpy() Numpy → Torch
- 이 둘을 변환하는 것은, 같은 메모리 공간을 공유하므로 하나가 변하면 다른 하나도 변함!! 그러나 GPU는 예외
Auto Gradient
- torch.autograd 는 텐서의 모든 연산에 대해 자동 미분을 제공함
- 이는 코드를 어떻게 작성하여 실행하느냐에 따라 역전파가 정의됨
- backprop을 위해 미분값을 자동으로 계산
- requires_grad를 True로 설정하면, 해당 텐서에서 이루어지는 모든 연산들을 추적함. #Default 는 False 기록에서 제외되길 원한다면, .detach()를 호출하여 연산기록으로부터 분리하면 됨
- grad_fn : 미분값을 계산한 함수에 대한 정보 저장 (어떤 함수에 대해 backpropagation을 했는지)
- backward(~~~) 함수로 자동으로 역전파 계산을 할 수 있고, grad에 data가 거쳐온 layer에 대한 미분값이 저장됨 ~~~의 값에 대하여 backprop.를 계산해줌
- with torch.no_grad()를 사용하여 기울기의 업데이트를 하지 않음
- detach() : 내용물은 같지만 requires_grad가 다른 새로운 텐서를 가져올때 필요
print(x.requires_grad) # False
y = x.detach()
print(y.requires_grad) # True
print(x.eq(y).all()) #tensor(True)
데이터 준비
- PyTorch에서는 데이터 준비를 위해 torch.utils.data에서 제공하는 Dataset과 DataLoader사용이 가능
- Dataset에는 MNIST, FashionMNIST, CIFAR10 등이 있음
- DataLoader와 Dataset을 통해 batch_size, train여부, transform등을 인자로 넣어 데이터를 어떻게 가져올 것인지 정해줄 수 있음
- torchvision은 PyTorch에서 제공하는 데이터셋들이 모여있는 패키지
- transforms는 전처리할때 사용하는 메소드를 제공하며, 이외의 전처리 방법은 클래스나 함수 만들어서 따로 진행할 수 있음
import torchvision.transforms as transforms
from torchvision import datasets- DataLoader의 인자로 들어갈 transform을 미리 정의할 수 있고, Compose를 통해 리스트안의 순서대로 전처리를 진행함
- ToTensor() 는 torchvision이 PIL Image형태로만 입력을 받기 때문에 데이터 전처리를 위해서 tensor형태로 변환을 해주어야함
mnist_transform = transforms.Compose([transfroms.ToTensor(), transforms.Normalize(mean=0.5,),std=(0.1,))])
trainset = datasets.MNIST(root=' ', train=True, download=True, transform = mnist_transform) #Train download with transform
#Test도 동일함
DataLoader는 데이터 전체를 보관했다가 실제 모델 학습을 할때 batch_size 크기 만큼 데이터를 가져옴
train_loader = DataLoader(trainset, batch_size=8, shuffle=True, num_workers=2)
#Test도 동일신경망 구성
- layer : 신경망의 핵심 데이터 구조로, 하나 이상의 텐서를 입력받아 하나 이상의 텐서를 출력
- module : 한 개 이상의 layer가 모여서 구성
- model : 한 개 이상의 module이 모여서 구성
- torch.nn 패키지 : 주로 weights, bias값들이 내부에서 자동으로 생성되는 layer들을 사용할때 사용. (weight 직접 선언 하지않음)
import torch.nn as nn
#nn.Linear
input = torch.randn(128,20)
m = nn.Linear(20,30) #input 20 feature, output 30 feature
output = m(input)
#nn.Conv2d
input = torch.randn(20,16,50,100) #20 batch 16 channel 50*100 size
m = nn.Conv2d(16,33,3, stride=2)
m = nn.Conv2d(16,33,(3,5) stride=(2,1), padding(4,2)) #다양한 convolution
output = m(input) # 20, 33, 26,100 -> 20 batch 33 out_channel ...
- nn.Conv2d argument: in_channels : channel 의 갯수 out_channels : output channel 의 갯수 kernel_size : 커널(필터) size
nn.Conv2d(in_channels=1, out_channels=20, kernel_size=5, stride=1)
#1channel 20 output channel, kernelsize 5,5 stride 1,1
layer = nn.Conv2d(1, 20, 5, 1).to(torch.device('cpu')) #Same meaning
#Weight 확인
weight = layer.weight #20,1,5,5
#Weight는 detach()를 통해 꺼내줘야 numpy()변환이 가능함
- Pooling layers F.max_pool2d : Stride, kernel_size 정의 가능 torch.nn.MaxPool2d 도 많이 사용
import torch.nn.functional as F
pool = F.max_pool2d(output, 2,2) #이런 식으로 풀링함
#MaxPool layer는 Weight이 없기 때문에 바로 numpy() 변환 가능
pool_arr = pool.numpy() 선형레이어 Linear Layers
- 1D만 가능하므로, .view() 또는 flatten 을 사용해 펼쳐줘야함
from torch.nn.modules import flatten
lin = nn.Linear(784, 10)(flatten)
lin.shape -> ([1,10])
비선형 레이어 Non-Linear Layers
- Softmax, ReLU 같은 activation function
##SoftMax
with torch.no_grad():
flatten = input_image.view(1, 28,28)
lin = nn.Linear(784,10)(flatten)
softmax = torch.nn.functional.softmax(lin, dim=1)
#ReLU
inputs = torch.randn(4,3,28,28).to(device)
layer = nn.Conv2d(3,20,5,1).to(device)
output = torch.nn.functional.relu(layer(inputs))모델 정의
- nn.Module 상속 클래스 정의
class Model(nn.module):
def __init__(self, inputs):
super(Model, self).__init__()
self.layer = nn.Linear(inputs,1)
self.activation = nn.Sigmoid()
def forward(self, x):
x = self.layer(x)
x = self.activation(x)
return x
print(list(model.modules())) # model의 구성 확인 가능- nn.Sequential 을 이용하여 Neural Network 정의 가능
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.layer1 = nn.sequential(
nn.Conv2d(in_channels=3, out_channels=64, kernel_size =5),
nn.ReLU(inplace=True),
nn.MaxPool2d(2)
)
self.layer2 = nn.sequential(
nn.Conv2d(in_channels=64, out_channels=30, kernel_size =5),
nn.ReLU(inplace=True),
nn.MaxPool2d(2)
)
self.layer3 = nn.sequential(
nn.Linear(in_features=30*5*5, out_features=10, bias = True),
nn.ReLU(inplace=True),
)
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = x.view(x.shape[0], -1)
z = self.layer3(x)
return xLoss Function
- 예측 값과 실제 값 사이 오차 측정
- 학습이 얼마나 잘 되어가고 있는지 나타내는 지표
- 모델이 훈련되는 동안 최소화 될 값으로 주어진 문제에 대한 성공 지표
- 손실 함수에 따른 결과를 통해 학습 파라미터를 조정
- 최적화 이론에서 최소화 하고자 하는 함수
- 미분 가능한 함수 사용
- PyTorch의 주요 손실함수:
criterion = nn.MSELoss()
criterion = nn.BCELoss()Optimizer
- 손실함수를 기반으로 모델이 어떻게 업데이트 되어야하는지 결정 (특정 종류의 확률적 경사 하강법 구현)
- optimizer는 step을 통해 전달받은 파라미터를 모델 업데이트
- 모든 옵티마이저의 기본으로 torch.optim.Optimizer(params, defaults) 클래스 사용
- zero_grad() 를 이용해 옵티마이저에 사용된 파라미터들의 기울기를 0으로 설정
- torch.optim.lr_scheduler를 이용해 epoch에 따라 Learning rate를 조절
- PyTorch의 주요 Optimizer:
Learning Rate Scheduler
- 일정 횟수 이상이 되면 학습률을 감소시키거나, Global minimum 근처에 가면 학습률을 줄이는 등 학습 시 특정 조건에 따라 학습률을 조정하여 최적화 진행
- PyTorch의 주요 Scheduler 종류:
Metrics ( 지표 )
- 모델의 학습과 테스트 단계를 모니터링
import torchmetrics
preds = torch.randn(10,5).softmax(dim=-1)
target = torch.randint(5,(10,))
print(preds, target)
acc = torchmetrics.functional.accuracy(preds, target)
print(acc)
#정확도 측정
metric = torchmetrics.Accuracy()
metric.compute() #해당 방법으로도 사용가능Summary : 선형 회귀 모델 돌려보기
X = torch.randn(200,1) * 10
y = X + 3 * torch.randn(200,1)
class LinearRegressionModel(nn.Module):
def __init__(self):
super(LinearRegressionModel, self).__init__()
self.linear = nn.Linear(1,1)
def forward(self, x):
pred = self.linear(x)
return pred
model = LinearRegressionModel()
w,b = model.parameters()
#Weight, Bias
criterion = nn.MSELoss()
optimizer = nn.optim.SGD(model.parameters(), lr = 0.001)
epochs = 100
losses = []
for epoch in range(epochs):
optimizer.zero_grad()
y_pred = model(X)
loss = criterion(y_pred, y)
losses.append(loss.item())
loss.backward()
optimizer.step()Summary : FashionMNIST 분류 모델
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
trainset = datasets.FashionMNIST(root = '', train=True, download=True, transform=transform)
#testset도 동일
train_loader = Dataloader(trainset, batch_size=128, shuffle=True, num_workers=2)
#testloader도 동일
labels_map = { 0:'T-shirt', 1:'Trouser', 2:'Pullover', 3:'Dress', 4:'Coat' . . .}
class NeuralNet(nn.Module):
def __init__(self):
super(NeuralNet, self).__init__()
self.conv1 = nn.Conv2d(1,6,3)
self.conv2 = nn.Conv2d(6,16,3)
self.fc1 = nn.Linear(16*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = F.max_pool2d(F.relu(self.conv1(x)),(2,2))
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(-1, self.num_flat_features(x))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
reutrn x
def num_flat_features(self, x):
size = x.size()[1: ]
num_features = 1
for s in size:
num_features *=s
return num_features
net = NeuralNet()
params = list(net.parameters())
criterion = nn.CrossEntropyLoss()
optimizer = nn.SGD(net.paramters(), lr = 0.001, momentum=0.9)
total_batch = len(train_loader)
for epoch in range(10):
running_loss = 0.0
for i, data in enemerate(train_loader, 0(:
inputs, labels = data
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 100 == 99:
print('Epoch:{}, Iter : {}, Loss : {}'.format(epoch+1, i+1, running_loss/100))모델의 저장 및 로드
- torch.save: net.state_dict() 를 저장
- torch.load: load_state_dict로 모델을 로드
PATH = ' .pth'
torch.save(net.state_dict(), PATH) #해당 위치에 저장해줌
net = NeuralNet()
net.load_state_dict(torch.load(PATH)) #모델 불러오기
모델 테스트
def imshow(image):
image = image/2 +0.5
npimg = image.numpy()
fig = plt.figuer(figsize ~)
plt.imshow(np.transpose(npimg, (1,2,0))) # 0번째를 맨 뒤로 해서 순서에 맞게 해주기
plt.show()