이번에 읽은 논문은 기본적인 GAN에 대한 논문으로 Self-Attention module을 적용한 GAN에 대한 논문입니다.. Transformer에서 사용되는 Self attention과 유사하게 적용되는 것 같습니다.
역시 마찬가지로 이해한대로 정리한 것이고 틀린 정보가 있을 수 있습니다.
Self-Attention Generative Adversarial Nets
Abstract
- 해당 논문은 Self-Attention GAN을 제안함
- Convolutional GAN은 높은 해상도의 디테일들을 저해상도의 feature map으로 생성하는 반면, Self-Attention GAN은 모든 feature location에서 얻은 힌트를 사용해 디테일을 생성함
- 더 나아가서 Discriminator는 먼 부분의 상세한 feature가 서로 일관되는지 확인함
- 정량적인 성능이 얼마나 개선됐는지 확인하고, Attention layer의 시각화를 확인
Introduction
- 기존의 모델인 Convolutional GAN은 Multi-class dataset에서 학습할 때, 다른 모델보다 모델링하는데 더 많은 어려움이 존재함
- 예를들어 Spectral Normalization GAN ( 당시 기준 SOTA ) 는 몇몇의 클래스에서 꾸준히 발생하는 geometric이나 structural pattern 를 캡쳐하는 것이 쉽지 않았음 (예를 들어 강아지들의 다리가 떨어져 있도록 생성)
- 하나의 추측 가능한 이유는 이전의 모델이 서로 다른 이미지 지역의 상호의존성에 대해 convolution에 심하게 의존한다는 점이라는 것
- Convolution은 local receptive field가 있기때문에, 전역적인 의존성(long range dependencies)은 여러 층의 Convolution layer를 거쳐야지 처리될 수 있음
- 하지만 이것은 장기 의존성(long-term dependices)의 학습을 어렵게 함
- 다시말해, 전역적인 의존성를 얻기 위해 여러층을 거치는데, 장기적으로 전파되는 의존성에 대한 학습은 어려워짐
- 그래서 나온 것이 Self-Attention인데, 효율적인 전역적인 상호의존성과 Computational, Statistical 능력을 모델링할 수 있음
- Self-Attention 모듈은 feature들의 weighted sum을 사용해서 적은 computational cost로 계산할 수 있음
- 해당 논문에선, 그래서 Self-Attention GAN을 제안했고, Convolutional GAN에 Self-Attention Mechanism을 적용했음
- Self-Attention 모듈은 convolution을 보완하고, 이미지 내의 지역들 사이의 전역적인, 다양한 레벨의 의존성을 모델링할 수 있도록 도와줌
- Generator는 세밀한 디테일을 구현할 수 있고, Discriminator는 더 정확하게 원본 이미지의 기하학적 속성을 유지하도록 해줌 (Geometric constraint란, 컴퓨터비전에서 이미지의 픽셀 간 위치관계, 객체의 형태와 위치, 카메라 시점 을 예시로 들 수 있음. 이미지 변환 작업에서 'enforce geometric constraint'는 변환된 이미지가 원본 이미지의 기하학적 속성을 유지하도록 강제하고 변환된 이미지가 원본 이미지의 형태, 위치, 방향 등의 속성을 올바르게 반영하게 하여, 변환의 정확도를 향상시킴)

Self-Attention GAN : Detail
- Convolution GAN은 지역의 이웃에 대한 정보를 처리하기 때문에 convolution layer를 단독으로 사용하는데, 이는 이미지내의 전역적인 의존성에 대한 모델링을 Computationally inefficient하게 함
- 그래서 해당 논문은 Non-local(지역이 아닌) 모델인 Self-Attention을 채택을 했고, Generator와 Discriminator가 넓게 떨어진 공간적인 지역으로부터의 관계를 효율적으로 모델링할 수 있게 해줌

- 이전 Hidden layer에서 온 image feature은 $x$ , 두개의 feature space $f, g$로 변환함 $f(x) = W_fx , g(x) = W_g x$
- 그리고 모델이 j번째 지역을 생성할 때 i번째 지역의 attend하는 정도를 나타내는 함수 $beta$는 $\beta_i,_j = exp(s_i,_j)/\Sigma_i^N exp(s_i,_j)$, $s_i,_j = f(x_i)^Tg(x_j)$
- 해당 결과는 $o = (o_1 , o_2 ...)$ 로 나타내고, $o_j = v(\Sigma_i^N \beta_j,_i h(x_i)), h(x_i)=W_hx_i , v(x_i) = W_vx_i$ 로 나타낼 수 있음
- 여기서 $W$는 학습된 weight matrix로 1x1 convolution으로 실행됨
- 위에서 언급한 Output은 Scale parameter와 input feature를 다시 더해서 최종 Output으로 나타냄 $y_i = \gamma o_i +x_i$
- $\gamma$= scale parameter, 학습가능한 parameter로 지역의 neighborhood에 대해 모델이 의존하도록 하게 해주고, 단계적으로 non-local 한 곳에 더 많은 weight을 할당하게끔 해줌
- 직관적으로 이 과정을 해석하자면 쉬운 작업부터 학습하고, 그 후에 복잡한 것으로 학습을 이동해서 하게끔 해줌
- SAGAN은 Attention module을 Generator, Discriminator에서 모두 사용하며, Loss function은 hinge version을 사용하여 나타냄
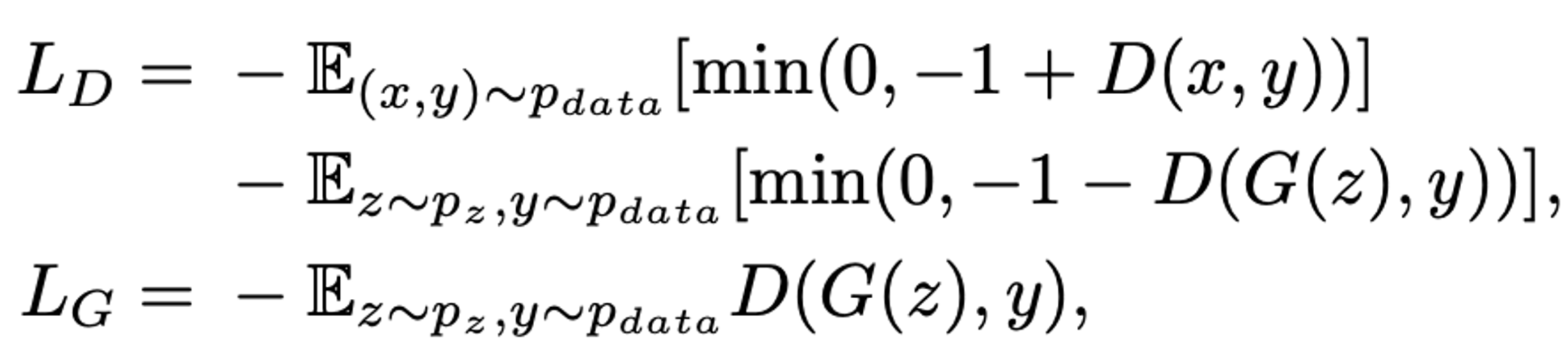
Techniques to Stabilize the Training of GANs
- 2가지 테크닉을 사용해서 GAN의 학습 과정을 안정시켰음
- Spectral Normalization 2) Two Timescale Update Rule
Spectral Normalization
- Miyato et al., Spectral Normalization GAN.은 Spectral Normalization을 사용해서 안정화 시켰고, 해당 기법은 추가적인 하이퍼파라미터를 필요로 하지 않으며 적은 computational cost가 든다는 것도 장점임 #Spectral Normalization : Layer weight 을 Largest Singular Value로 나누며, Lipschitz Constant가 사용되는데 이는 유일한 하이퍼파라미터임. 자세한 사항은 논문 SN-GAN에서 확인
- Generator에서 사용된 Spectral Normalization은 파라미터의 단계적 확대를 방지할 수 있고, 불필요한 Gradient를 피할 수 있음 또한 Generator와 Discriminator에 사용하는것이 Generator 업데이트 대비 적은 Discriminator의 업데이트를 가능하게함
- 따라서 이것이 학습의 Computational cost의 감소라 말할 수 있음
Two Timescale Update Rule (Imbalanced learning rate)
- 이전의 작업들에서 Discriminator의 regularization은 GAN의 학습 진행을 느리게 함
- Heusel의 논문은 Generator 와 Discriminator에서 서로 다른 Learning rate를 사용하도록 함, 이것이 바로 Two Timescale Update Rule = TTUR
- TTUR은 느린 학습의 문제를 보상하고, Generator 스텝 대비 더 적은 Discriminator 스텝을 하게 함
- 이러한 접근들을 사용하여 더 좋은 결과를 얻을 수 있었음
Experiments
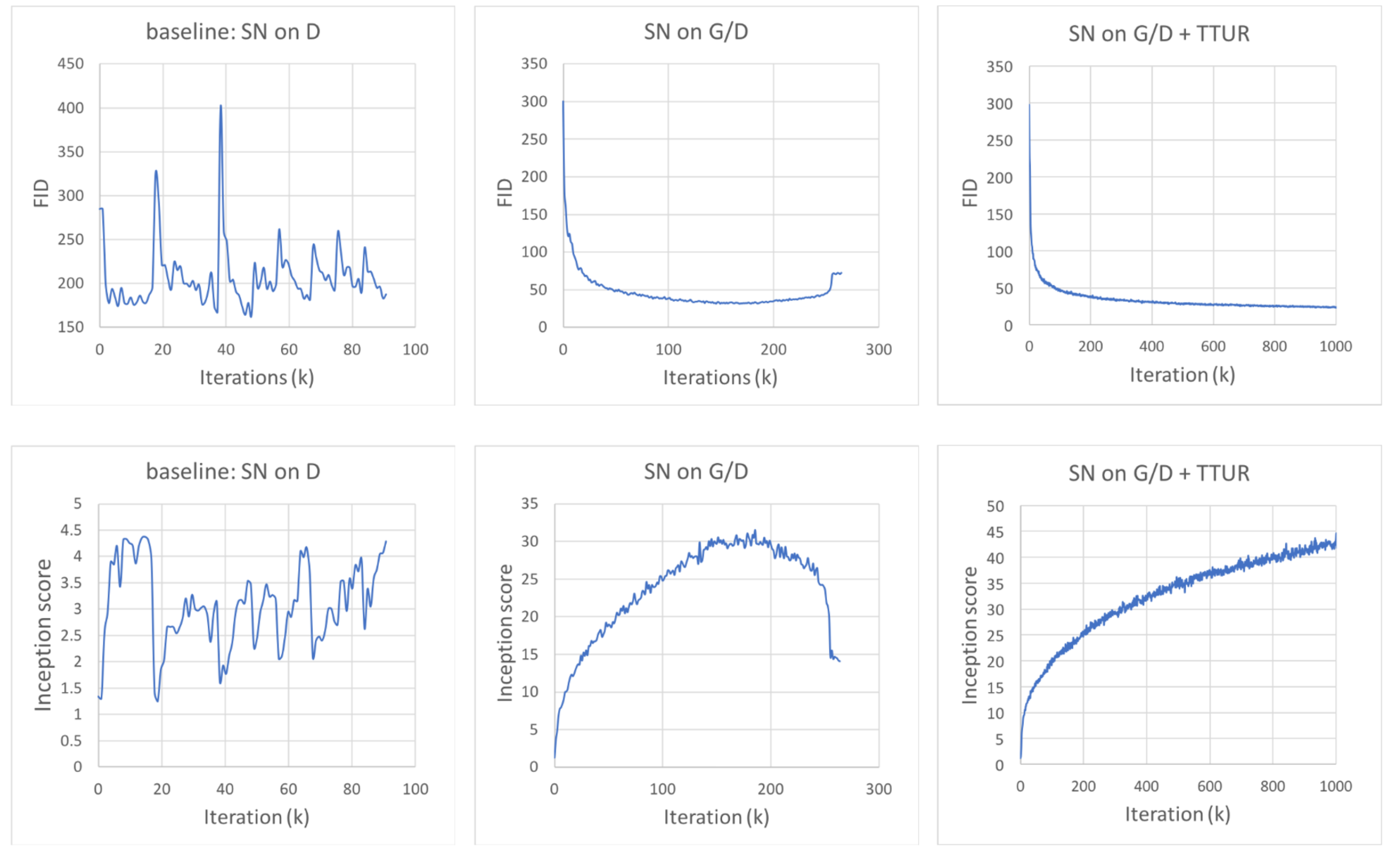
- 좌측은 Baseline, spectral normalization을 discriminator에 사용한 것, 중간은 Generator, Discriminator 모두 spectral normalization 사용, 우측은 TTUR까지 추가한 결과.
- TTUR이 없을때 FID가 감소하다가 증가하는 것 확인(적은 값이 좋음), IS 가 높아지지 않고 낮아짐 ( 높은값이 좋음)
- TTUR이 있을때 FID가 감소, IS가 증가하는 것 확인

- 생성된 결과로 확인할 수 있는 결과
- Attention map에 대한 Visualization
- 해당 사진들은 SAGAN의 결과물이며, 첫번째 사진은 3개의 색깔 점들이 representative query location을 나타냄
- 그 옆의 3개의 사진은 attention map을 나타내고, 각 화살표는 가장 attend한 지역을 나타냄 첫번째 사진을 예시로 보면 빨간점은 새의 몸에.. 배경의 초록 점은 반대편 배경을 , 꼬리는 몸과 연관이 있음을 보여줌 따라서 네트워크가 색깔의 유사도나 Texture에 의해서 attention을 학습하는 걸 알 수 있음
- 또한 공간적 위치에 대해 점이 있는 것을 볼 수 있고 attention map이 다른 것을 확인 가능
- 2번째 사진인 개의 사진을 봤을때, 다리가 깔끔히 분리되어 그려진 것도 확인할 수 있음

- 기존 SOTA와 비교했을때 결과.
어쩌다보니 BigGAN을 읽기전에 해당 논문부터 읽게 되었네요. 내용이 간단했던것도 있고 꼭 알아야할 것 같은 논문 같아서 먼저 읽게 되었습니다. 추가로 DCGAN에 대해서도 읽어봐야겠구요.. 정말 읽을게 많네요