이번 논문은 GAN에 추가적인 옵션?이 달린 GAN에 대한 논문입니다. 상위 Multi-modal 논문을 읽다보니 Conditional GAN이나, Instance condtioned GAN에 대한 지식이 필요하더라구요.. 그래서 새로운 지식을 습득해보고자 읽어봤습니다! GAN에 대해 좀 알고..? 확률적인 부분, 분포에 대해서 머릿속으로 이미지 메이킹을 해보면 어떻게 작동하는지 조금은 어림잡을 수 있습니다.
마찬가지로 제가 이해한대로 정리하고 틀린 부분이 존재할 수 있습니다.
Conditional Generative Adversarial Nets
Abstract
- 조건부 버전의 GAN
- 새로운 데이터 y를 사용하여 Generator 와 Discriminator에 조건을 부여하려함
- 멀티 모달에서 어떻게 사용되는지 확인
Introduction
- GAN은 상호작용가능한 확률계산을 추측하는데 생기는 어려움을 피할 수 있음
- 마르코프 체인이 사용되지 않는 다는 것이 장점이고, 오직 역전파만 사용됨
- 추론 또한 학습에 필요없고 넓고 다양한 요소와 상호작용이 포함되어 있음
- “Unconditioned” 생성모델은 생성되는 데이터에 대한 mode(modal) control이 필요없음
- 추가적인 정보로 모델을 조건화하는 것은 데이터 생성 과정에 지시하는 것(to direct)이 가능해짐
- 이러한 조건화는 클래스 라벨이나, inpainting을 위한 데이터 일부분이나, 다른 모달리티의 데이터로 기반이 됨
Related work
- 첫번째 문제는 매우 큰 양의 예측 결과 카테고리에 적응할 수 있도록 모델을 확장하는 것
- 두번째 문제는 현재까지(to date) 많은 작업들은 일대일 맵핑으로부터 초점이 맞춰져있지만, 많은 관심 문제는 일대다맵핑 문제
- 예를 들어 이미지 라벨링에는 많은 다른 태그들이 있음.
- 첫번째 문제 해결은 다른 모달리티에서 추가적 정보를 활용하는 것으로 해결가능
- 두번째 문제 해결은 조건부확률 생성모델을 사용하는 것으로 해결 가능 (조건 변수 y 사용)
Conditional Adversarial Nets
- Conditional model을 확장시킨 네트워크, extra information y를 사용.
- y는 클래스 라벨이나 다른 모달리티에서 온 데이터가 될 수 있음
- 조건화를 구현할 수 있는데 이는 Generator 와 Discriminator에 y를 입력함으로써 구현가능
- Generator에선 이전의 노이즈 z와 y 를 joint hidden representation에서 결합함
- Discriminator에선 x와 y를 입력과 Discriminative 함수로 나타냄 (embodied 되어있음)

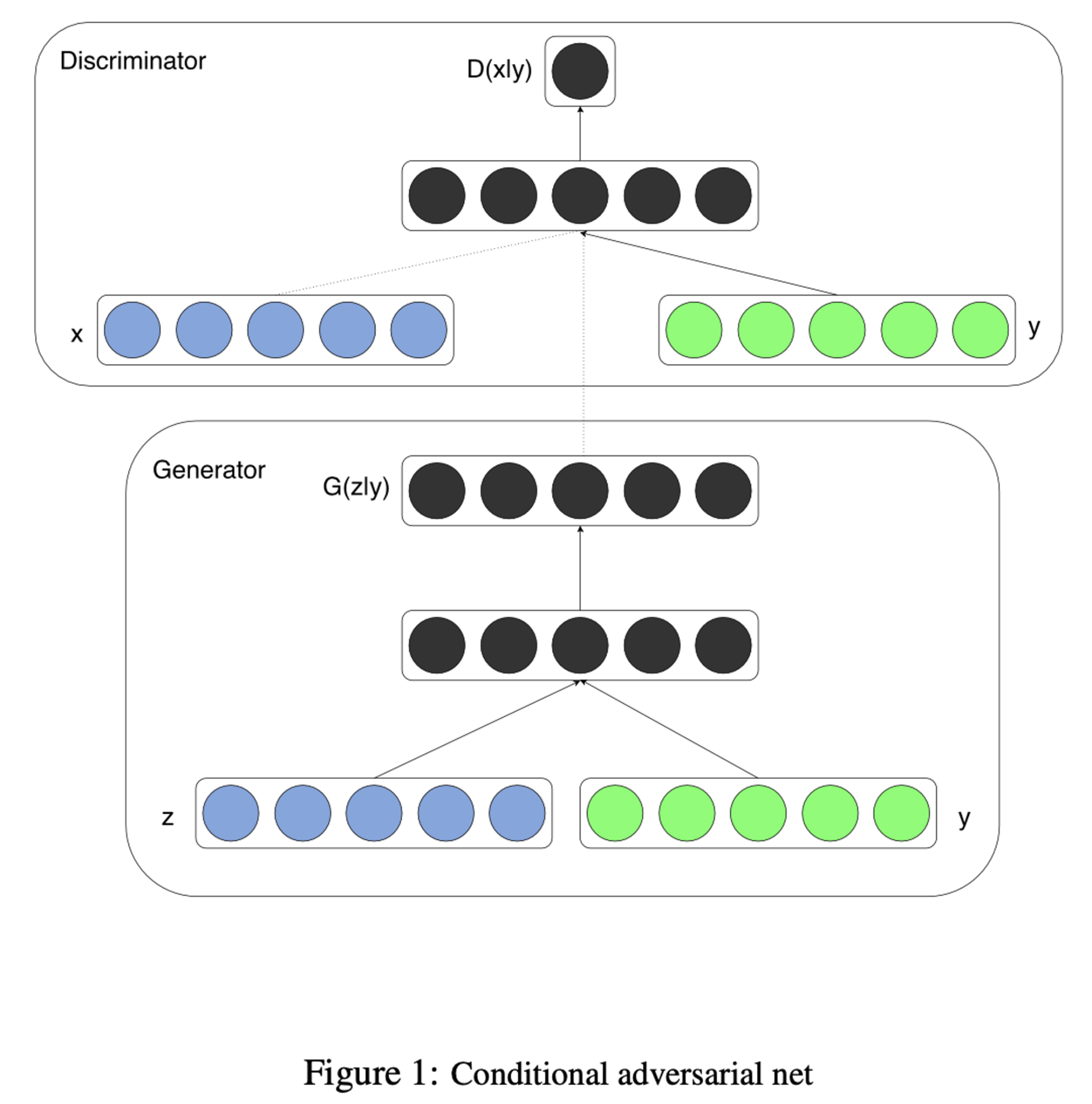
Multimodal Training
- 해당 모델에서는 자동으로 생성시키는 이미지 태그를 증명하고, Conditional adversarial net을 사용해서 multi-label prediction 진행
- Image feature를 위해 Pre-trained된 Convolutional model를 사용하였고, (사용한 모델은 ImageNet의 Classification을 위한 모델) 마지막 layer의 결과물(4096) 사용하였음
- Word representation을 위해, YFCC100M dataset을 사용하였다고 명시하였음. Corpus를 모아 전처리 후, Skip-gram model를 학습하였음
- 그리고 200 회보다 적게 등장하는 단어에 대해서는 생략하였고, 결과물에 대해선 247465 사이즈의 Dictionary를 생성하였음
- 실험을 위해 MIR Flickr dataset을 사용하였으며 위에 제시된 모델을 통해 image feature와 tag feature를 추출하였음
- 아무 태그도 없는 이미지들은 생략되었으며, annotation은 추가 태그로 처리되었음 (15만장 학습, 여러 태그가 있는 이미지는 반복)
- Evaluation단계에선, 100개의 생성이미지와 상위 20개의 가까운 의미의 단어를 코사인 유사도를 통해 찾아내었으며, 그 후 상위 10개의 단어를 선택하였음
- 가장 좋은 결과를 내는 모델의 Generator는 100 size의 Gaussian noise를 사용하였고, 해당 노이즈를 500 dimension ReLU 층에 투영하였음
- Discriminator는 500, 1200 dimension의 ReLU 로 구성되어있고, 이는 Word vector와 image feature를 위해 사용됨. Maxout layer는 join layer에서 사용되며 해당 결과물은 최종적으로 하나의 단일 sigmoid input으로 사용됨
- 각종 parameter들과 hyper-parameter들은 Paper에 제시

해당 부분까지가 Conditional GAN에 관한 내용입니다.
Multi-modal에 대해 어떻게 GAN이 사용되었는지 확인하려고 해당 부분을 위주로 찾아보았고, 어떻게 학습시켰는지를 확인했습니다.
이어서 IC-GAN에 대한 내용입니다.
Instance-Conditioned GAN
Introduction
- GAN은 성공적임에도 불구하고 최적화의 어려움과 Mode Collapse가 발생함
- 이는 Generator가 좋은 분포를 생성해 내거나 저품질의 샘플을 생성할 수 있음
- 많은 시도가 있었지만 복잡한 데이터분포(예를 들어 ImageNet)에선 해당 문제들이 계속 이어졌다함
- Class-conditional GAN은 Class label을 조건화하여, 데이터분포를 학습하기 쉽도록 해줌
- 하지만 이는 Label 데이터를 필요로 하고, Cost가 필요함
- 몇몇 최근의 접근은 GAN 성능의 향상을 위해 Unsupervised data partitioning을 사용함
- 하지만 역시 이도 Class-conditional GAN에 비하면 퀄리티가 매우 떨어짐
- Unsupervised Data paritioning은 조잡하고 겹치지않는 Data partition을 사용하고, Data는 각 다른 타입의 물체나 장면이 포함되어있음
- 이러한 데이터의 다양성은 파티션의 낮은 밀도의 결과를 낳으며, 생성된 이미지의 퀄리티 저하를 일으킴
- 그래서 더 미세하게 파티션을 진행해본 결과, 클러스터는 너무 적은 데이터를 포함하고 결과를 더 악화시킴
- 해당 논문에선 새로운 접근을 가지며, 이는 Instance-conditioned GAN (ICGAN)
- ICGAN은 GAN을 확장시켜 Local data density를 만듦
- ICGAN은 Data point의 Neighborhood의 분포를 만들도록 학습되며, 각 Data point는 “Instance”라고 함
- 이러한 학습은 Instance의 representation을 Generator와 Discriminator 모두에 Input으로 사용함으로 진행
- 또한 이러한 학습은 Instance의 neighbor을 “real” sample로 사용하여 Discriminator에 사용
- 조건으로 주어진 Instance 주변의 충분하게 큰 neighborhood를 선택함으로써 ICGAN은 위에서 말한, 미세하게 파티션으로 나누는 것을 피할 수 있음
- 더 나아가, Instance representation의 조건은 Generator가 Instance와 비슷한 sample을 생성할 수 있게 해줌
- 또한 ICGAN은 Instance 조건을 교체시켜, 보지 못한 데이터셋으로 이를 전이시킬 수 있음
- ICGAN은 Kernel Density Estimation과 유사한 방법을 사용하지만 kernel에 의존하지않고, kernel bandwith parameter 또한 Neighborhood의 크기를 선택하는 걸로 대체할 수 있음
- 해당 논문에선 ICGAN을 두 가지 task로 나누어 진행 : Unlabel image generation, Class-condtional image generation
- Unlabel 데이터는 ImageNet과 Coco-stuff를 사용하였고, 두 데이터셋 모두 이전의 접근보다 나은 결과를 나타내는 것을 확인할 수 있었음
- Class-conditional에서는 class condition을 사용해 이미지를 생성, 마찬가지로 퀄리티와 다양성 확보

- a)는 unlabel, b)는 class-condtional c)와 d)는 ImageNet으로 학습된 모델에 다른 데이터셋을 적용하여 얻은 결과
Method
- ICGAN의 중요 아이디어는 Fine-grained overlapping cluster를 활용하여 복잡한 데이터셋의 분포를 구성함
- 각각의 클러스터는 Instance들이 포함되어 있고, Nearest neighbor들로 이루어져있음.
- Data distribution p(x)를 mixture of condtional distributions p(x|h)로 나타내는 것을 목표로 함
- h는 Instance feature vector이며, 클러스터는 M개의 instance로 이루어져 있고, 따라서 $p(x) = 1/M \Sigma_i p(x|h_i)$
- 더 구체적으로, 주어진 Unlabel 데이터 D는 M개의 Data sample($x_i$)로 되어있고, Embedding fuction가 feature을 추출함. $h_i = f(x_i)$
- 여기서 Embedding function은 비지도 학습이나 자기지도학습을 통해 학습됨
- 그 이후, 코사인 유사도를 사용하여 $k$ nearest neighbors를 측정하여 클러스터 $A_i$ 를 정의함

- 해당 모델은 implicitly하게 conditional distribution $p(x|h_i)$를 Generator를 사용하여 모델링하기를 원함
- Generatorms GAN에서와 동일하게 Gaussian prior $z ~N(0,I)$ 를 위 Conditional distribution을 사용해 변환함
- 마찬가지로 적대적 접근을 사용하여 Generator를 학습하였음
- 따라서 Generator는 Discriminator와 함게 학습되는데, “Real neighbor”와 “Generated neighbor”를 구별하도록 학습됨
- 각각의 $h_i$, Real neighbor은 KNN으로 정의한 셋 A에서 옴
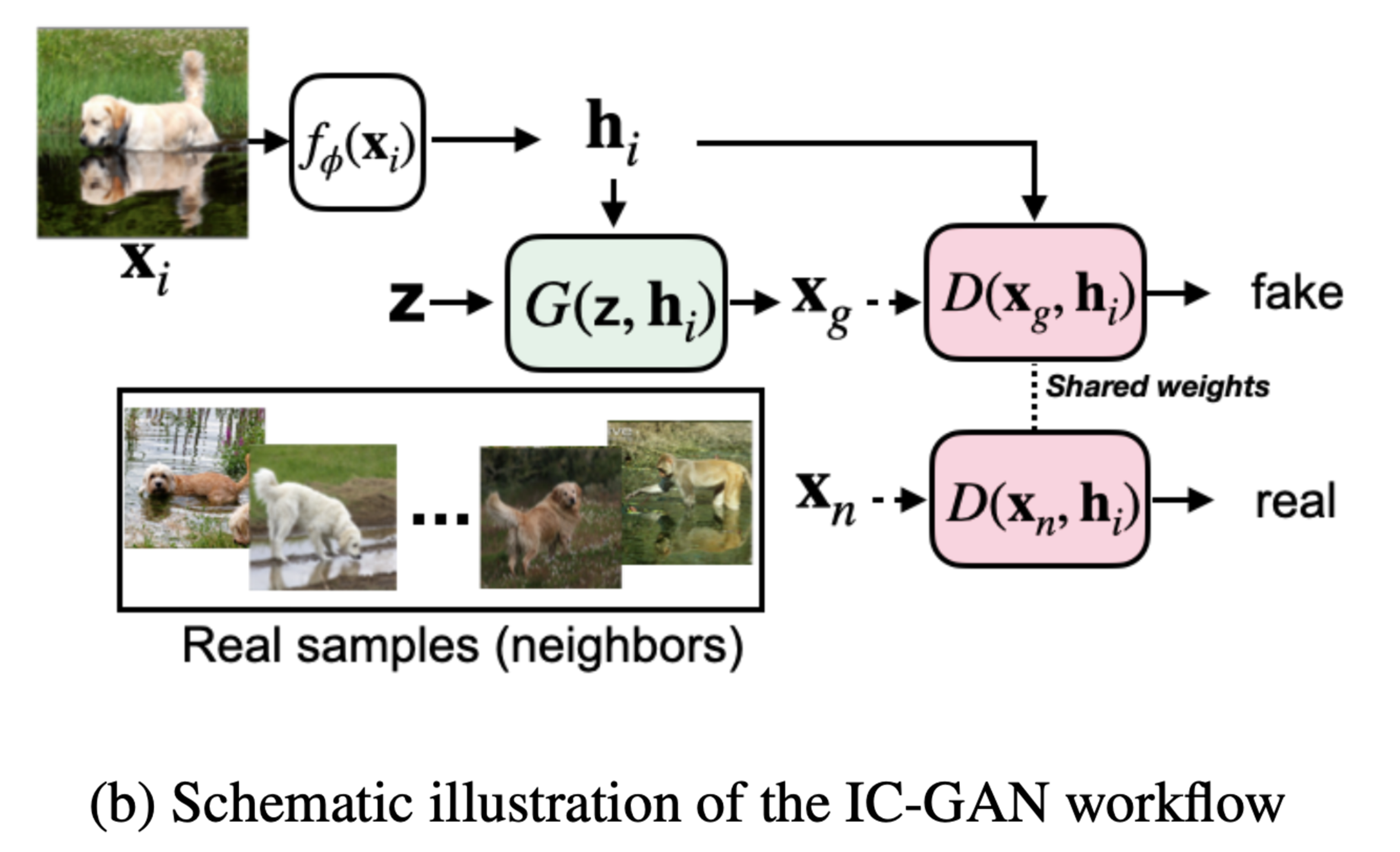
- Generator와 Discriminator는 GAN과 같이 Two player min-max game으로, 아래 수식과 일치

- Class-conditional의 경우, Class label y를 사용하여 추가적으로 Generator와 Discriminator에게 조건화해줌
- 해당 경우 Data는 $D_l = \{(x_i, y_i)\}^M_i$ 로 되어 있고, 마찬가지로 Feature를 $h_i = f(x_i)$로 적용
- 해당 경우 기본적일때와 동일하게 Embedding fuction이 비지도 학습, 자기지도 학습으로 학습될 수 있지만, 자기지도 학습의 경우도 포함됨
- 마찬가지로 A의 셋을 KNN으로, 코사인 유사도를 사용하여 정의함
- 학습엔, 셋 A에서 Real neighbor $x_j$ 와 세트인 label $y_j$ 추출해서 적용
- 따라서 Generator 와 Discriminator를 사용하여 $p(x|h_j, y_j)$를 모델링함
주석 1. Inpainting : 작품의 손상, 열화 또는 누락된 부분을 채워 완전한 이미지를 제공하는 보존 프로세스. 이 프로세스는 일반적으로 이미지 복원에 사용
주석 2. Model Collapse: Generator가 다양한 Fake image를 만들어 내지 못하고 비슷한 image만 계속 생성하는 상태, 많은 양의 이미지를 동일한 color나 texture로 생성할때 발생하며 주로 Generator와 Discriminator 학습의 불균형으로 발생
주석 3. Local density: 데이터 공간에서 특정 지점 주변의 데이터포인트의 밀도를 나타냄
주석 4. Kernel Density Estimation: 커널함수와 데이터를 바탕으로 연속성 있는 확률밀도함수를 추정하는 방법
주석 5. GAN에서도 Data Augmentation이 사용되는데, 이는 Discriminator에 Input되기 전에 사용됨
노션에서 바로 넘겨오니 수식이 깨지네요..실제로 논문을 몸으로 느껴(?)보려면 코드를 돌려야할텐데 못돌려봤네요.
우선 BigGAN과 GAN에 대한 Review paper까지 싹 리뷰한 후에 돌려볼만한게 있는지 확인해봐야겠습니다.