ViLBERT에 대해 논문을 읽고 제가 이해한 대로 정리하여 PPT로 만들어보았습니다.
Transformer 구조는 언제보아도 흥미롭네요. 어떻게 저런걸 생각해냈을지..

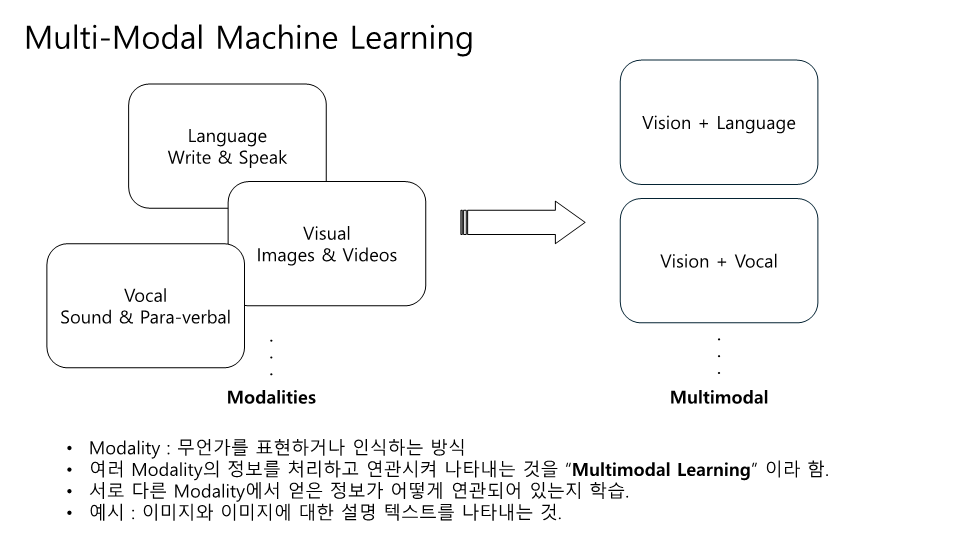
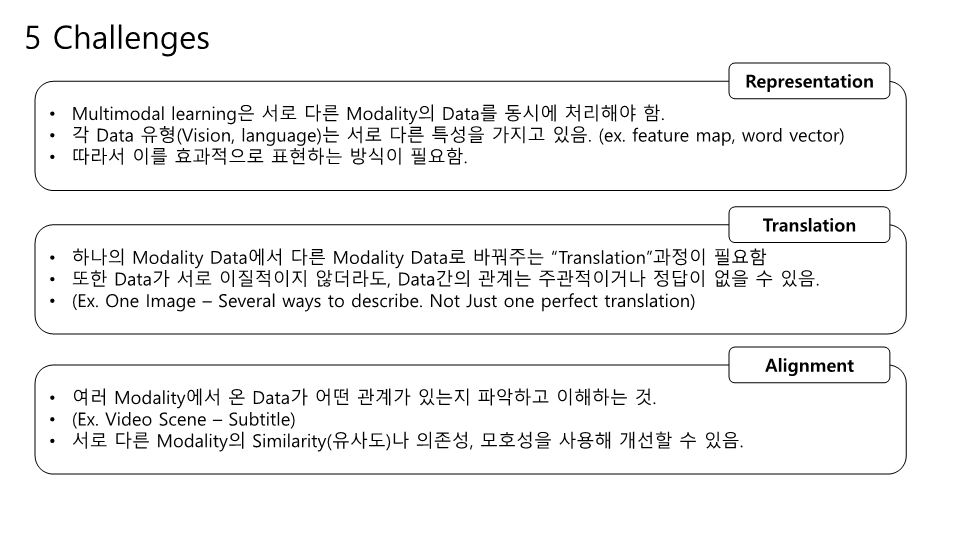

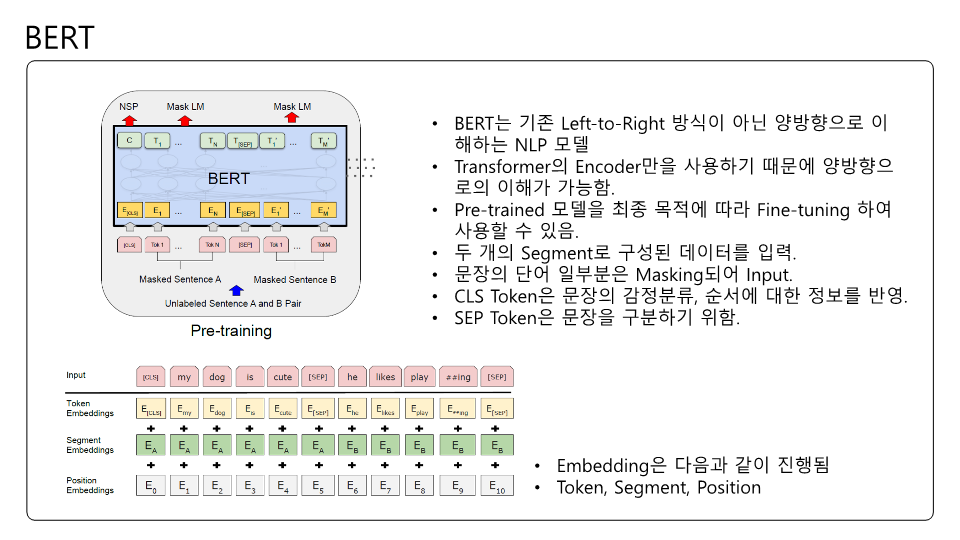



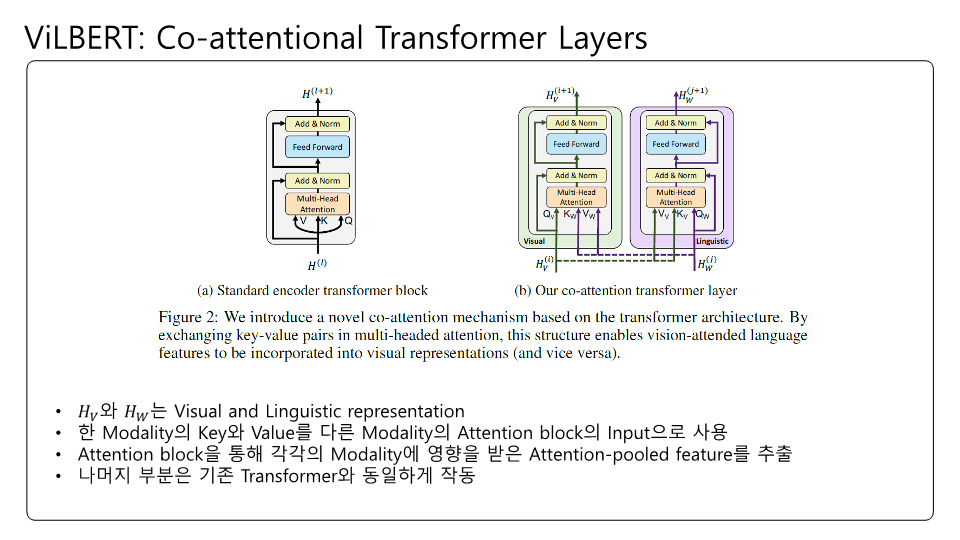

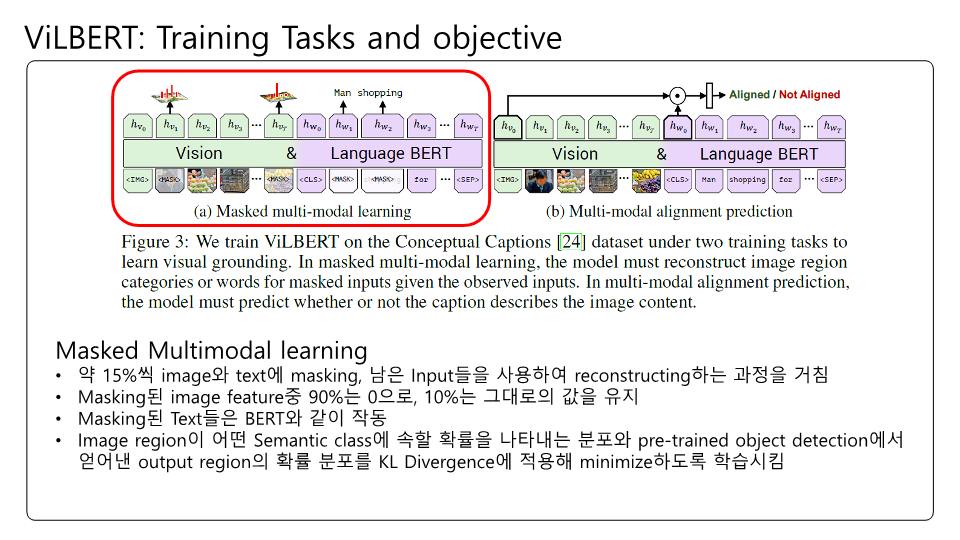
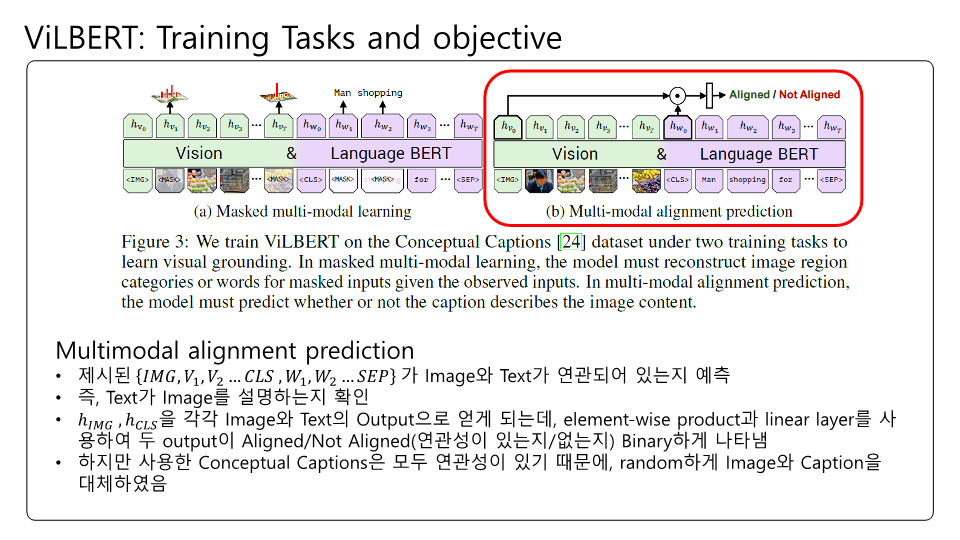

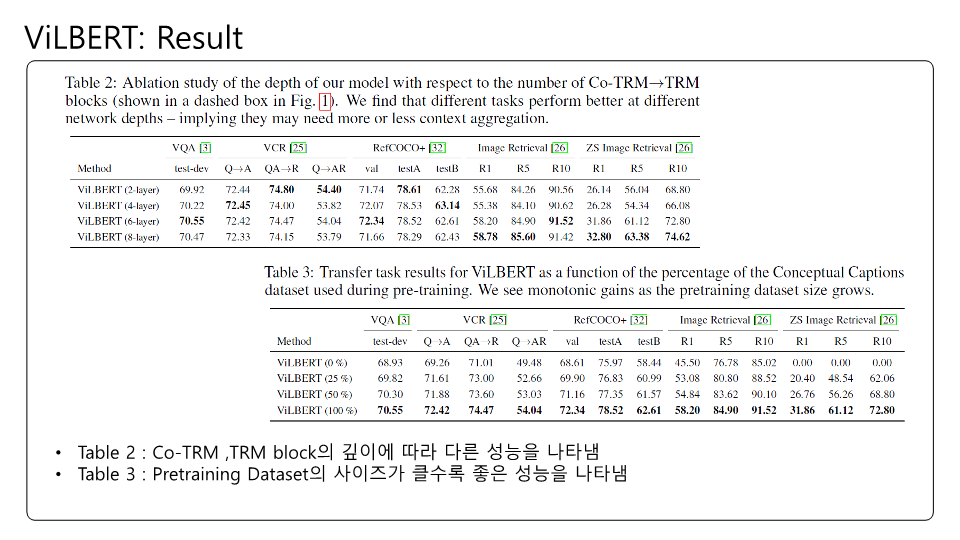

잘못된 내용이 존재할 수 있습니다! BERT의 구조를 다시한번 생각해보느라 이해하는데 꽤 시간이 걸렸던 것 같네요.
'Deep Learning' 카테고리의 다른 글
| Yolo V5 cutout Augmentation (2) | 2024.01.29 |
|---|---|
| Paper Review: Speech2Face: Learning the Face behind a Voice(IEEE 2019) (0) | 2024.01.29 |
| Yolo V5 Validation. (0) | 2024.01.15 |
| Yolo V5 Training. (2) | 2024.01.12 |
| AdaIN으로 생성한 Data의 이름과 json을 수정해보자! (0) | 2024.01.11 |