1. read_html()로 파일읽기
import pandas as pd
krx_list = pd.read_html('C:/Users/hards/Downloads/상장법인목록.xls')
krx_list[0].종목코드 = krx_list[0].종목코드.map('{:06d}'.format) #종목코드 0생략들을 커버함 {:06d]는 여섯자리 숫자형식으로 표현
print(krx_list[0]) #리스트의 첫번째 원소 출력
print('\n')
df = pd.read_html('https://kind.krx.co.kr/corpgeneral/corpList.do?method=download&SearchType=13')[0] #URL을 이요해 인터넷 상 파일 읽기 뒤의 [0]은 결과를 데이터프레임으로 받음
df['종목코드'] = df['종목코드'].map('{:06d}'.format) #마찬가지로 여섯자리 숫자형식으로 표현
df = df.sort_values(by = '종목코드') #오름차순 정렬
print(df)2. BeautifulSoup 사용으로 일별 시세 분석하기
from bs4 import BeautifulSoup
import pandas as pd
import requests
url = 'https://finance.naver.com/item/sise_day.naver?code=005930&page=1'
html = requests.get(url, headers={'User-agent' : 'Mozilla/5.0'}).text
bs = BeautifulSoup(html, 'lxml') #첫번째 인수로 html/xml 페이지 넘겨주고, 두번째 인수로 파싱할 방법 : lxml (속도가 매우 빠르고 유연한 파싱) 선택
pgrr = bs.find('td', class_='pgRR') #find함수를 통해 마지막 페이지를 탐색
print(pgrr.a['href']) #html 속성을 사용해 맨뒤 페이지 획득
print(pgrr.prettify()) #pgRR의 전체 텍스트 확인
print(pgrr.text) #태그를 제외한 text부분
s = str(pgrr.a['href']).split('=') #split함수를 사용해 리스트로 나타내기
print(s)
last_page = s[-1] #해당 리스트에서 마지막 인덱스 호출 = 마지막 페이지
print(last_page); print('\n')
df = pd.DataFrame()
sise_url = 'https://finance.naver.com/item/sise_day.naver?code=005930' #시세확인 url
for page in range(1, int(last_page)+1): #1부터 마지막페이지+1 까지 반복
url = '{}&page={}'.format(sise_url, page) #url은 format함수를 사용함
html = requests.get(url, headers={'User-agent' : 'Mozilla/5.0'}).text #request 라이브러리 사용, 웹페이지 요청
df = df.append(pd.read_html(html, header=0)[0]) #요청한 웹페이지 분량의 데이터프레임을 추가
df = df.dropna() #NaN행 제거
print(df)3. KAKAO 종가차트 구하기 실습
import pandas as pd
import requests
from bs4 import BeautifulSoup
from matplotlib import pyplot as plt
url = 'https://finance.naver.com/item/sise_day.naver?code=035720&page=1'
html = requests.get(url, headers={'User-agent':'Mozilla/5.0'}).text
bs = BeautifulSoup(html, 'lxml')
pgrr = bs.find('td', class_='pgRR')
s = str(pgrr.a['href']).split('=')
last_page = s[-1]
df = pd.DataFrame()
sise_url = 'https://finance.naver.com/item/sise_day.naver?code=035720'
for page in range(1, int(last_page)+1):
url = '{}&page={}'.format(sise_url, page)
html = requests.get(url, headers={'User-agent': 'Mozilla/5.0'}).text
df = df.append(pd.read_html(html, header=0)[0])
df = df.dropna() #NaN 제거
df = df.iloc[0:30] # 30개의 종가 데이터 사용 , 슬라이싱
df = df.sort_values(by='날짜') #날짜순으로 배열, 오름차순
plt.title('KAKAO(Close)')
plt.xticks(rotation=45) #겹치는 경우가 있으므로 x축의 텍스트 방향을 45도로 기울여 사용
plt.plot(df['날짜'], df['종가'], 'co-') #x축은 날짜, y축은 종가로 하여 그래프 생성, 'co-' 는 좌표를 초록점으로, 점끼리 잇는 선을 실선으로
plt.grid(color='gray', linestyle='--') # 그리드는 회색 점선으로 표현
plt.show()
4. Naver OHLC 와 Candle차트 구하기 실습
import pandas as pd
import requests
from bs4 import BeautifulSoup
import mplfinance as mpf
url = 'https://finance.naver.com/item/sise_day.naver?code=035420&page=1'
html = requests.get(url, headers={'User-agent' : 'Mozilla/5.0'}).text
bs = BeautifulSoup(html, 'lxml')
pgrr = bs.find('td', class_='pgRR')
s = str(pgrr.a['href']).split('=')
last_page = s[-1]
df = pd.DataFrame()
sise_url = 'https://finance.naver.com/item/sise_day.naver?code=035420'
for page in range(1, int(last_page)+1):
url = '{}&page={}'.format(sise_url, page)
html = requests.get(url, headers={'User-agent': 'Mozilla/5.0'}).text
df = df.append(pd.read_html(html, header=0)[0])
df = df.dropna() #NaN제거
df = df.iloc[0:30] #0부터30번째 까지 슬라이싱
df = df.rename(columns={'날짜': 'Date', '시가' : 'Open', '고가' : 'High' , '저가' : 'Low' , '종가' : 'Close' , '거래량' : 'Volume'}) #이름을 재정의하기, 한글칼럼명을 영문칼럼명으로 변경
df = df.sort_values(by='Date') #날짜별로 오름차순으로 정렬
df.index = pd.to_datetime(df.Date) #인덱스를 Date칼럼으로 변경
df = df[['Open', 'High', 'Low', 'Close', 'Volume']] #해당 열만 갖도록 데이터프레임 구조 수정
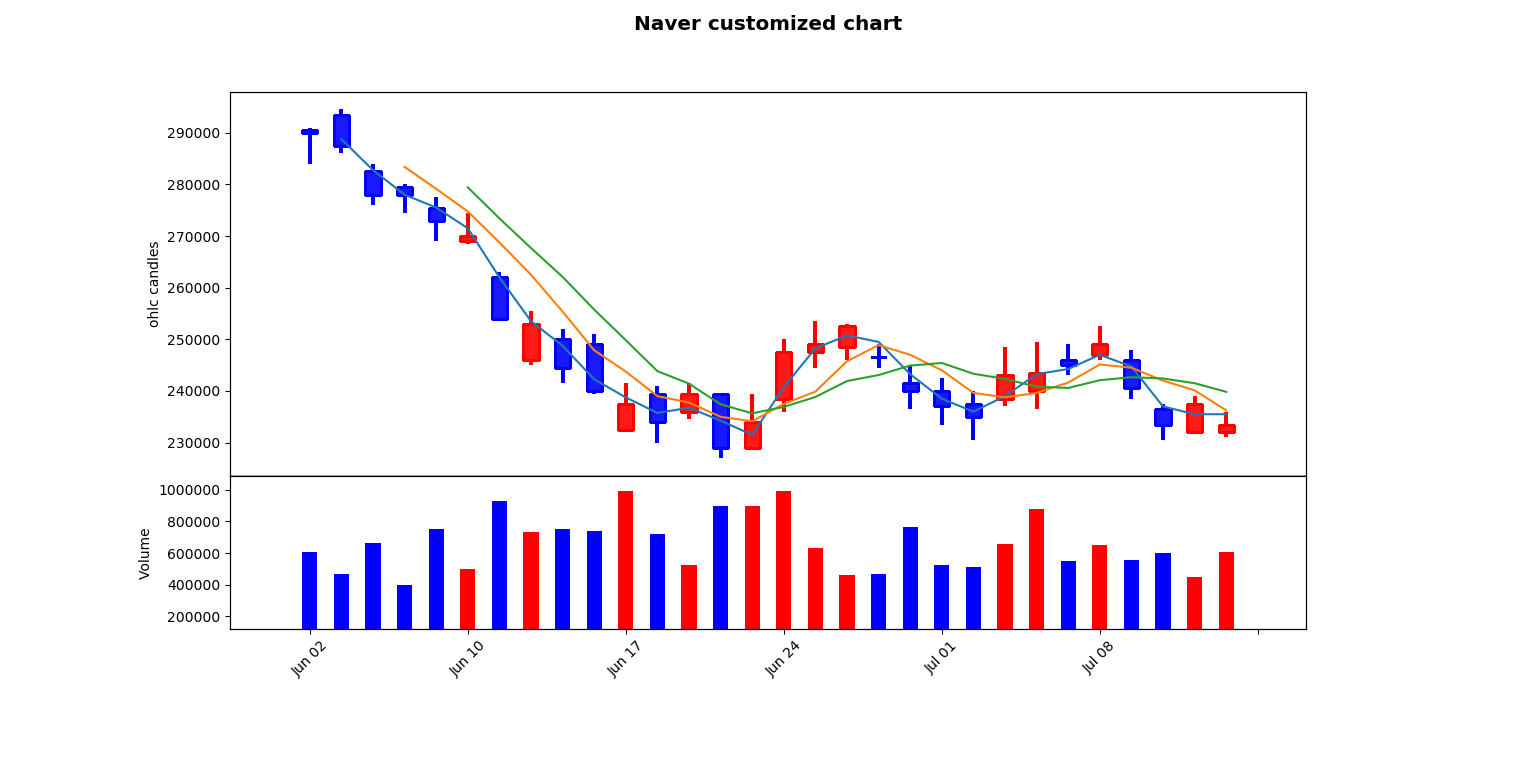
mpf.plot(df, title='Naver Candle chart') #캔들차트 출력
#mpf.plot(df, title='Naver ohlc chart', type='ohlc') : ohlc차트로 출력
#이동 평균선 삽입
kwargs = dict(title='Naver customized chart', type = 'candle', mav=(2, 4, 6), volume=True, ylabel='ohlc candles') #kwargs는 keyword arguments의 약자, 여러 인수를 담는 딕셔너리
mc = mpf.make_marketcolors(up='r', down='b', inherit=True) #마켓 색상은 스타일을 지정하는 필수 객체 , 상승 : 빨강, 하강: 파랑
s = mpf.make_mpf_style(marketcolors=mc) #마켓색상을 인수로 갖는 스타일 객체 완성
mpf.plot(df, **kwargs, style=s) #df을 x축으로 갖고, 여러인수를 y축으로 가지며 style이 s인 그래프 완성
'Electronic Engineering > Python data analysis' 카테고리의 다른 글
| Python Data 분석 : MariaDB를 활용한 시세 조회 (0) | 2022.07.27 |
|---|---|
| Python Data 분석 : yfinance와 네이버금융 데이터로 시세조회하기(실패) (0) | 2022.07.19 |
| Python Data 분석 : 미국국채와 코스피의 회귀분석 (0) | 2022.07.06 |
| Python Data 분석 : 상관계수에 따른 리스크 완화 (0) | 2022.07.06 |
| Python Data 분석 : 선형 회귀분석과 상관관계 (0) | 2022.07.06 |