회귀분석을 통해 연속적인 데이터 Y와 해당 Y의 원인이 되는 X간의 관계를 찾아 선형회귀모델 식을 구해 임의의 X값이 주어질 경우 Y를 예측하는 과정을 Scipy와 Pandas를 사용하여 분석
import pandas as pd
from pandas_datareader import data as pdr
import yfinance as yf
yf.pdr_override()
dow = pdr.get_data_yahoo('^DJI', '2000-01-04') #다우존스 데이터 추출
kospi = pdr.get_data_yahoo('^KS11', '2000-01-04') #코스피 데이터 추출
import matplotlib.pyplot as plt
plt.figure(figsize=(9, 5)) #그래프 크기를 9X5로 정의
plt.plot(dow.index, dow.Close, 'r--', label='Dow Jones Industrial') #다우존스의 그래프
plt.plot(kospi.index, kospi.Close, 'b--', label='KOSPI') #코스피의 그래프
plt.grid(True) #그리드 표시
plt.legend(loc='best') #주석 달기
plt.show()
#일별 종가만으로는 상관관계를 분석하기 힘듬
#특정시점의 종가로 나누어 분석
d = (dow.Close/dow.Close.loc['2000-01-04'])*100 #금일종가를 2000년1월4일 종가로 나눈후 100을 곱함
k = (kospi.Close/kospi.Close.loc['2000-01-04'])*100 # 마찬가지로 금일 종가를 해당 값으로 나눔
plt.figure(figsize=(9, 5)) #그래프 크기 정의
plt.plot(d.index, d, 'r--', label= 'Dow Jones Industrial') #다우존스 그래프 x축은 Index, y축은 d값
plt.plot(k.index, k, 'b--', label='KOSPI') #코스피 그래프 x축은 index, y축은 k값
plt.grid(True) #그리드 생성
plt.legend(loc='best') #주석은 최선의 위치에.
plt.show()
print(len(dow)); print(len(kospi)) #각 데이터의 양 산점도 그래프를 그리기 위해서는 x와 y의 값이 같아야함.
print('\n')
df = pd.DataFrame({'DOW' : dow['Close'], 'KOSPI' : kospi['Close']}) #각 종가 열을 합쳐서 데이터프레임 형성, 이 경우 같은양의 데이터가 됨. 하지만 NaN이 존재
print(df); print('\n') #NaN이 존재하며 이는 산점도함수 사용 불가
df = df.fillna(method='bfill') #NaN뒤에 있는 값으로 NaN을 채워줌. 하지만 마지막열에서 NaN이 있는것을 확인할 수 있음.
df = df.fillna(method='ffill') #마지막 열에 NaN이 있으므로 추가적으로 함수를 적용
print(df)
plt.figure(figsize=(7,7)) #산점도 함수 그래프의 크기
plt.scatter(df['DOW'], df['KOSPI'], marker='.') #x축은 dow 지수, y축은 kospi지수, 점으로 표현한다.
plt.xlabel('Dow Jones Industrial Average') #x축 이름은 다우존스
plt.ylabel('KOSPI') #y축 이름은 코스피
plt.show()
from scipy import stats #싸이파이 호출
model = stats.linregress(df['DOW'], df['KOSPI']) #선형회귀모델 계수 구하는 함수
print(model) #기울기(slope) = 0.075 , y절편(intercept) = 487.4 따라서 Y의 기대치 E(X) = 487.4 + 0.075X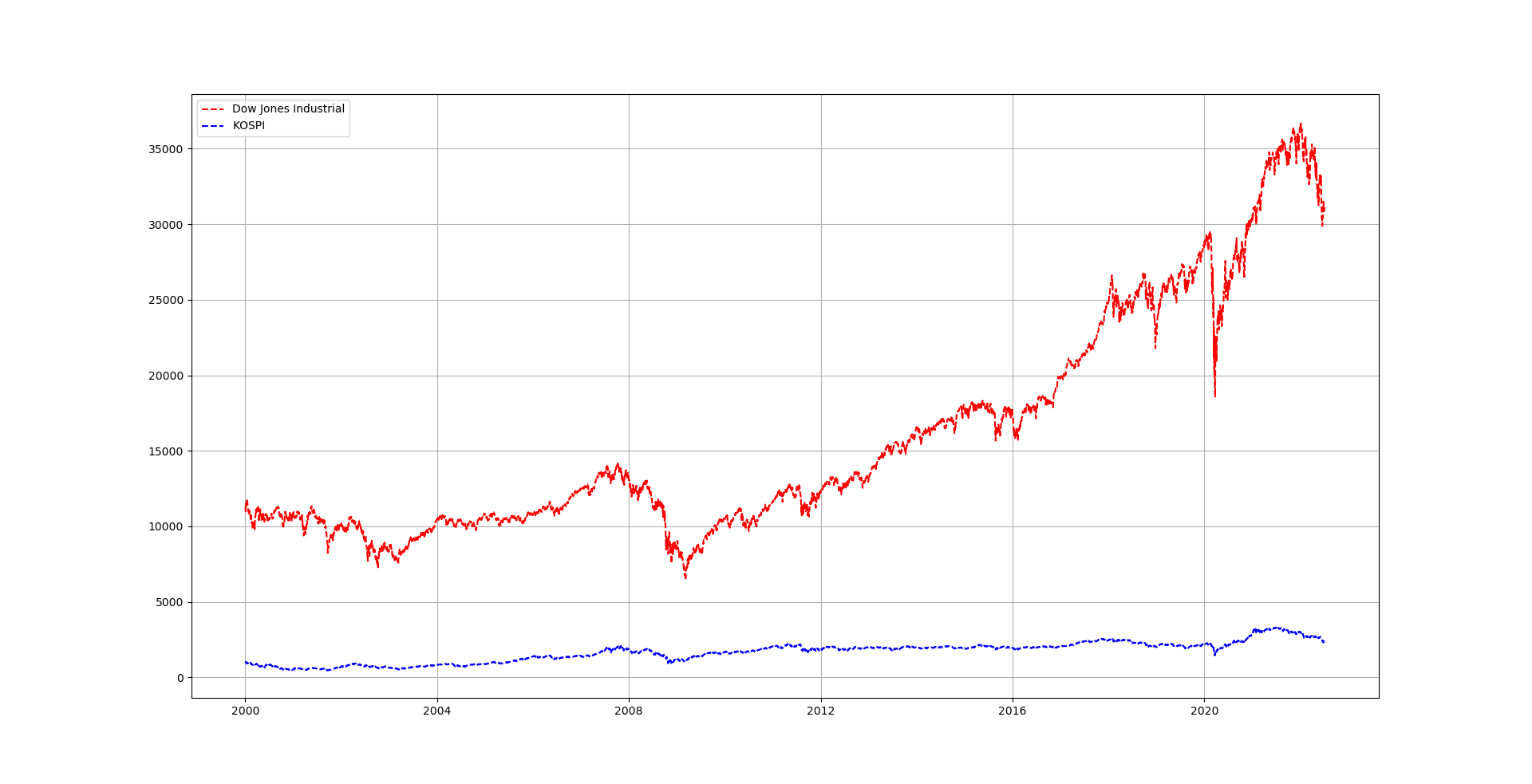


'Electronic Engineering > Python data analysis' 카테고리의 다른 글
| Python Data 분석 : 미국국채와 코스피의 회귀분석 (0) | 2022.07.06 |
|---|---|
| Python Data 분석 : 상관계수에 따른 리스크 완화 (0) | 2022.07.06 |
| Python Data 분석 : Kospi MDD (0) | 2022.07.06 |
| Python Data 분석 : yfinance를 이용한 주식수익률 비교 (0) | 2022.07.06 |
| Python Data 분석 - Using yfinance (0) | 2022.07.06 |